
In this blog we show how simple it is to configure AI to run against different asset types as a business user. Moving on to an example of both an image then a video and the tags created. There is then an example of the Vision OCR Service in action where it identifies text in an image and the language that text is in. Touching on other analysis feature such as identifying additional metadata and duplicates. Potential for future functionality is explored, hoping to show how excited we about these features and believe strongly that Content Hub can provide extreme value that will only be built upon in future versions. The topics covered are as follows:
- Easily Trigger AI Analysis Based on Asset Type
- Automate Content Tagging and Enrichment
- Identify Text and Duplicates
- Future Potential
Easily Trigger AI Analysis Based on Asset Type
A key Taxonomy for most assets in Content Hub is Asset Type. Some out of the box options can be seen below but it is simple to add additional options.
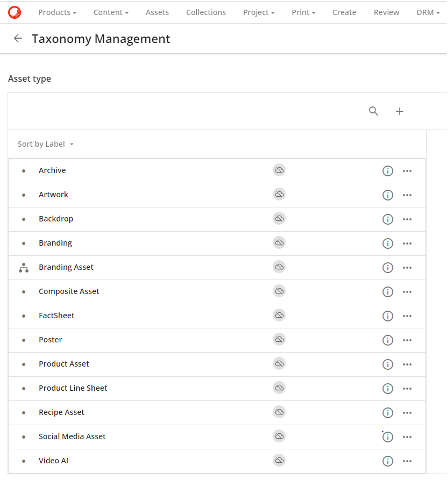
On creation of an Asset Type Taxonomy there are the toggle options seen in the following image which need no developer input to setup.
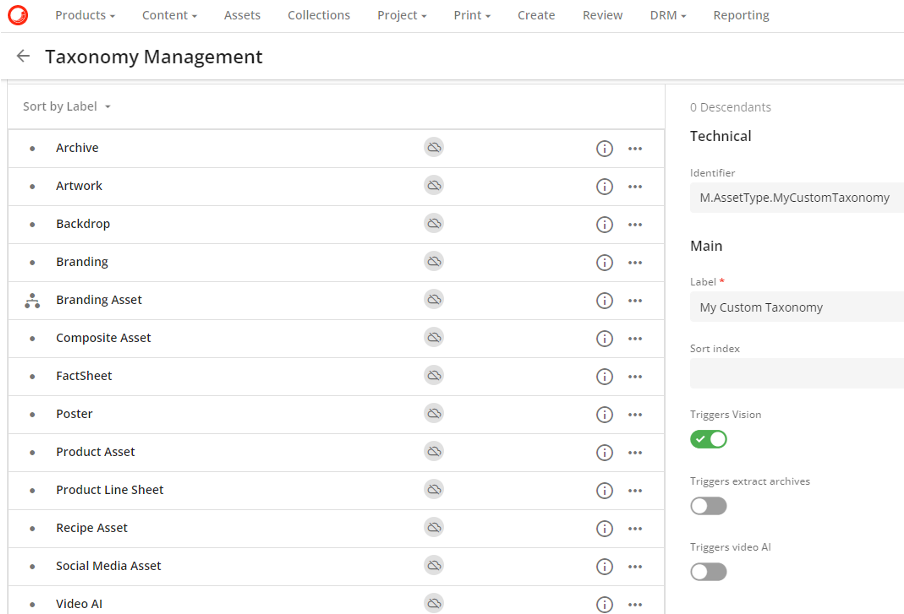
Automate Content Tagging and Enrichment
Below can be seen an example image and the tags from the assets image analysis are, “person”, “soft drink”, “food”, “fast food”, “girl”, “drink”, “bottle”, “summer”, “beach”. Not perfect but a good start.
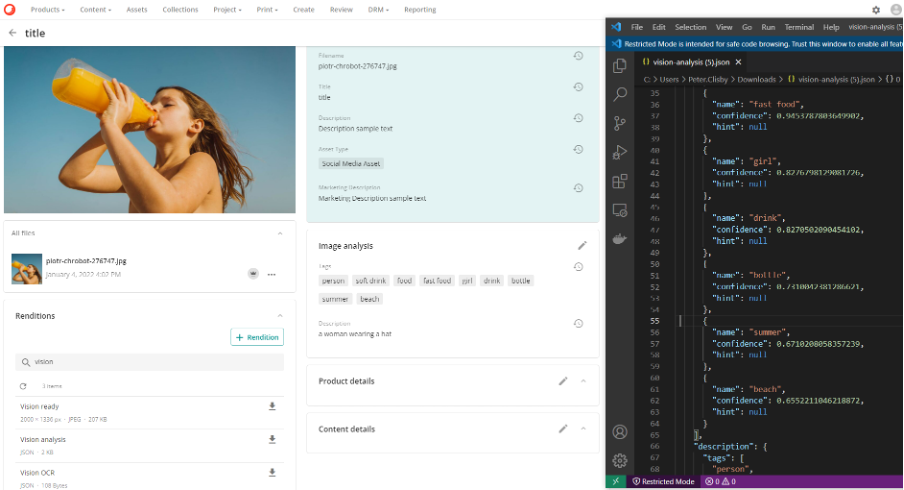
The JSON output of the Image Analysis is stored as a rendition on the asset and can be downloaded as shown on the right-hand side above. Interestingly, it suggests a confidence of around 65% that the image is taken on a beach. There’s nothing clear in the image to suggest it’s on a beach but a human might say 50-50 it probably could be. Then the reviewer can make the decision, eliminating the first round of content enrichment. Alongside reducing the need for developer input the value provided by Content Hub starts to become clear.
Below a video can be seen which the JSON output of the analysis on the right-hand side has the following tags; "person", "people", "group", "man", "holding", "posing", "standing", "photo", "sitting", "child", "food", "young", "table", "wine", "smiling", "boy", "woman", "wearing", "riding", "court", "boat", "player".
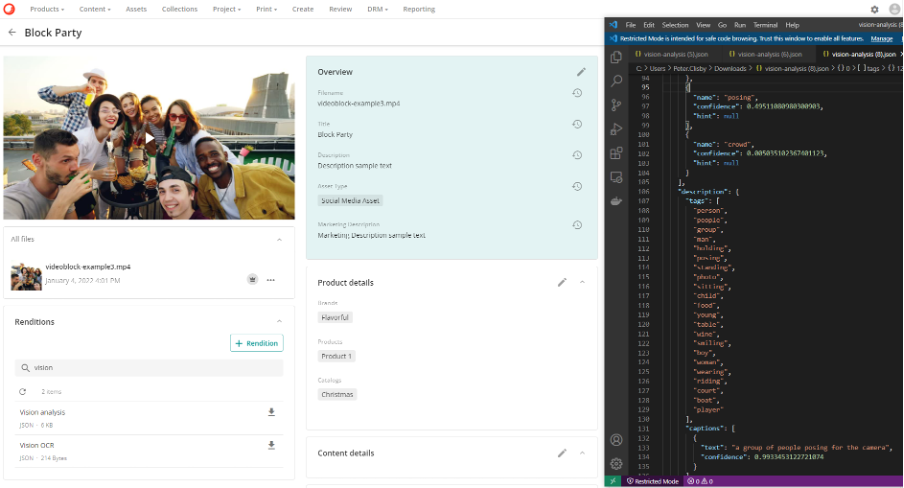
There is also other information available such as dominant colours, stated to be “white”, “grey”, and “brown”. These can all be reviewed and overridden or discarded if incorrect.
Identify Text and Duplicates
Other AI capabilities available in Content Hub include the ability to identify where there are similar images that could be considered duplicates. Assisting with ensuring consistency and maintainability.
Furthermore, the OCR (Optical Character Recognition) Vision Service can identify text in assets as well as the language in many cases. Again, in some scenarios this can identify data that the human brain might struggle to, for example, a content reviewer might identify the text but not know which language and need to take additional time to look this up. Or the text orientation might be upside-down, leading the human reviewer to not understand it correctly or miss it altogether.
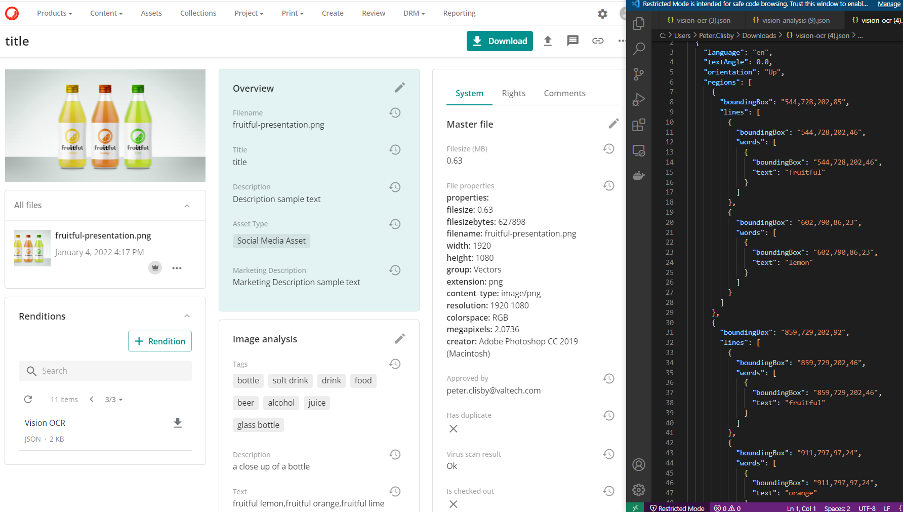
The [Text] member has been populated with the words “fruitful lemon”, “fruitful orange”, “fruitful lime”. You can see on the JSON output on the right-hand side that it’s identified the language as English (en), as well as even the orientation of the text being “Up”. It also describes the image in the [Description] member as “a close up of a bottle”. You could rightly say that there are three bottles not “a bottle” but again it’s a good starting point.
Other analysis can be seen such as an indicator of [Has duplicate], virus scanning, and other metadata such as the creator of the image being in Photoshop.
Future Potential
As the AI analysis features of Content Hub mature, alongside it’s capabilities beyond a simple DAM such as CMP and PCM, there’s huge potential for further gains. Product companies are already able to use Microsoft Cognitive Services to train a model to identify their products.
Take a scenario where a workman wants to purchase parts and can photograph the part they need, upload the photo, and the supplier’s system use AI to identify the product they want to purchase. Saving the customer time figuring out the part reference number or trawling through products online to find it. This concept could be very powerful in Content Hub if able to tag uploaded images with the products they relate to. There are endless other possibilities which make a future involving Content Hub very exciting. A true best of breed DAM offering and much more.
Catch up on the other articles in this series:
Sitecore Content Hub – Media Processing Automation: Part 1 – No Code
Sitecore Content Hub – Media Processing Automation: Part 2 – Low Code




