Text detection
The first text detector we explored was tesseract, an open-source OCR engine maintained by Google. We used the pytesseract library to interface with it from our existing code. With this setup, we can extract text from any image with 1 line of code, and as it runs locally it is quick to set up and test.
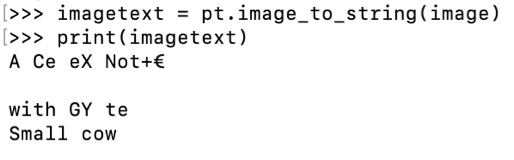
Our results were pretty poor. We had some success with block capitals but most of the sticky notes we tried to read returned a very messy string, something completely random, or nothing at all. Using a few different sticky notes we found the accuracy to be around 10%

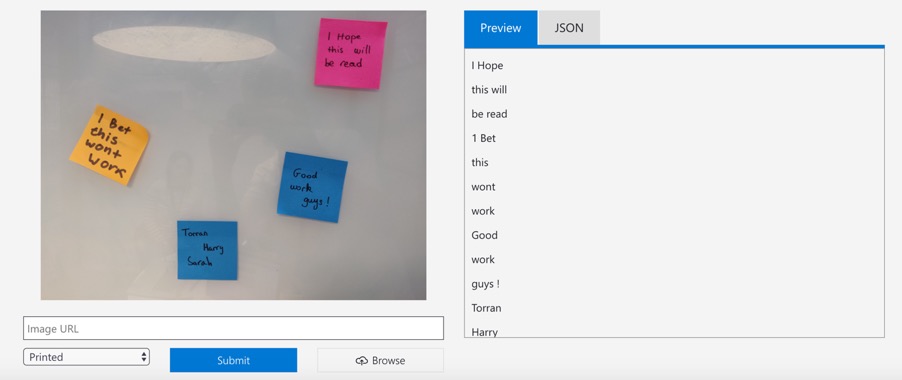
The output from running the tesseract OCR engine on the sticky note shown:
So far, we had passed tesseract the full-colour images cropped from the object detector, to try and improve the results we experimented with several image processing methods to make the text clearer.
Firstly, we increased the contrast. This had mixed results, with accuracy increasing on some images but decreasing on others. Lighter coloured sticky notes appear clearer whilst dark coloured ones become less legible.
As recommended on the tesseract repo, we also tried thresholding the images. This method sets all pixels below a given threshold to black and all those above it to white, creating a binary image. With this technique, we can isolate the text from the background without any information about the sticky note itself getting in the way. We tried a few different ways of deciding which threshold to use. Our first attempt used 128, the midpoint of the greyscale pixel values. We had better success using k-means clustering on the pixel values to find groups of similar shades of grey e.g. text, sticky note and background, and using these to find a threshold between the text and the sticky note.
Even with these alterations, we were not very successful. This is likely because tesseract is optimised for reading printed documents and it has trouble recognising handwriting without retraining. Our sticky note reader had to recognise all handwriting, so even with retraining, we would not be able to get it to recognise the text we wanted.
Searching further we found a blog post [4] about training a handwriting detector, linked to a repo containing a pre-trained model. After cloning this and integrating it with our current pipeline we tested the model on our colour images and our pre-processing techniques but again had poor results.
Finally, we tested the OCR cognitive service offered by Microsoft Azure. This is a paid cloud service requiring calls to an azure server to carry out text detection. We tried the service by uploading a few images to their demo page and the accuracy on those images was much better than our previous attempts, achieving around 80%. It was fairly easy to set up a free trial and activate an endpoint we could use to detect text on sticky notes. Colour images gave us the best results, so we did not do any pre-processing or try to make the text clearer.