




outubro 30, 2019
How we automated the conversion of physical sticky notes to digital cards in Trello
Introduction
We’ve all been there; you’ve got to the end of long, stimulating meeting and have amassed a board FULL of sticky notes. More often than not, these contain a plethora of useful information that should be recorded in a more permanent fashion than a feeble sticky note.
This results in some poor soul being burdened with the tiresome task of manually typing out the seemingly endless stack of sticky notes. After being on the receiving end of this thankless task one too many times, we decided it was time for change. We set about developing a way to automate this process in a web app using a combination of machine learning, cloud services and web frameworks.
Similar concepts [1] have been toyed with in the past; but these either involve sticky note recognition or text detection, we decided to combine these to get relevant text outputs and not just cropped, sticky note, images.
We even thought to take it one step further and have the option to upload the sticky notes to a Trello board automatically! If you’ve ever used Trello before you will understand how useful it can be as a tool for coordinating and managing the progress of a project from planning to evaluation. A Trello board is a great way to visualise and categorise tasks and assign these to group members to keep everyone in the loop and on track.
In this blog post we will guide you through the development and investigation process as we worked towards an operational application.

Sticky note Detection
The first challenge encountered was the need to find a way to detect and isolate each individual sticky note on the board so that further processing could be carried out. We considered several different computer vision techniques including edge detection and colour detection, but, from previous experience we were aware of how unreliable this could be. In the end, we decided the best approach would be to train a sticky note, object detection, machine-learning model, using Google’s Tensorflow Object Detection API. We used a couple of tutorials online to get us on our way. [2][3]
The steps required to achieve this were:
- Collect a dataset of sticky note images.
- Label these sticky notes with bounding boxes and export the XML.
- Produce a label map.
- Split the dataset into training and test data and generate TFRecord files for each.
- Write a configuration file.
- Begin training on local machine and monitor progress using Tensorboard.
We collected 45 images of sticky note boards, trying to select images that were relatively clear but with a variety of colours, angles, lightings and orientations. We annotated these images, one by one, using LabelImg; an open-source, graphical image annotation tool.
Just 45 images would ordinarily constitute a relatively small dataset; however, in our case, each image contained multiple sticky notes, therefore, our final training dataset contained about 800 bounding boxes and our test dataset about 150. These were then converted into the necessary TFRecords file format using Tensorflow’s python script.

As we were only training our object detector to detect one item our label map was very simple:
item {
name:'stickynote'
id: 1
}
The final stage was to write a configuration file to describe the training of the model. It is possible to start training from scratch, but to simplify the process the training can be started from a pre-existing checkpoint; we decided to do this, starting from a checkpoint trained on the COCO dataset and the relevant config file. Once a few minor changes were made to the config file, so that it was suitable for our purposes, the training could be started by running the model_main.py script. It was left to run for 5k steps and monitored on Tensorboard.
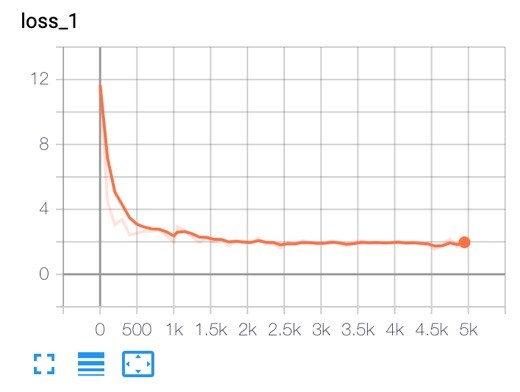
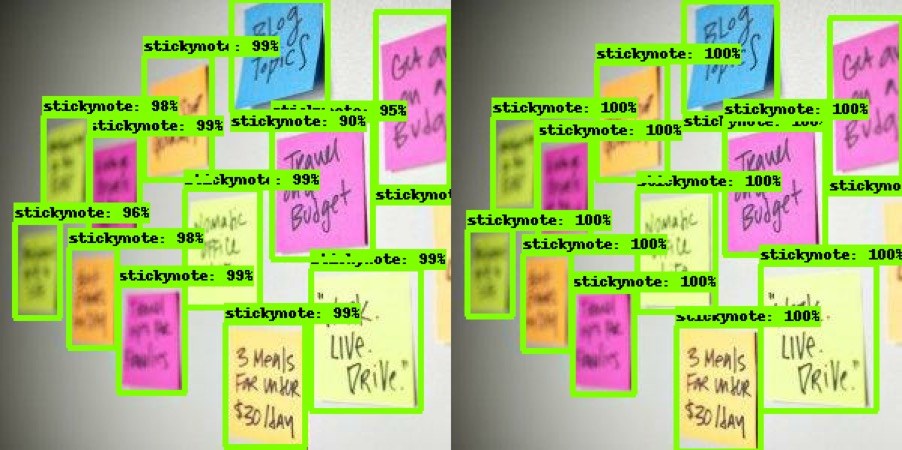
The loss graph from Tensorboard shows how the model reduced errors as it progressed through the steps. The Tensorflow loss function is a sum of the classification loss and localisation loss, the closer it is to 0 the better the model; our model reached a value of about 2. The mean average precision (mAP) of detection from our test data reached about 60% and the recall almost 70%. A larger dataset and more steps could have yielded better results but considering the time available our model was more than adequate, and we had labelled enough sticky notes for one life-time. The image below shows our models predictions on the left and the actual bounding boxes on the right; as you can see, for this photo, it finds all the sticky notes with a high probability.
We could now freeze and export the model’s graph and use it for inference!
Text detection
The first text detector we explored was tesseract, an open-source OCR engine maintained by Google. We used the pytesseract library to interface with it from our existing code. With this setup, we can extract text from any image with 1 line of code, and as it runs locally it is quick to set up and test.
Our results were pretty poor. We had some success with block capitals but most of the sticky notes we tried to read returned a very messy string, something completely random, or nothing at all. Using a few different sticky notes we found the accuracy to be around 10%

The output from running the tesseract OCR engine on the sticky note shown:

So far, we had passed tesseract the full-colour images cropped from the object detector, to try and improve the results we experimented with several image processing methods to make the text clearer.
Firstly, we increased the contrast. This had mixed results, with accuracy increasing on some images but decreasing on others. Lighter coloured sticky notes appear clearer whilst dark coloured ones become less legible.
As recommended on the tesseract repo, we also tried thresholding the images. This method sets all pixels below a given threshold to black and all those above it to white, creating a binary image. With this technique, we can isolate the text from the background without any information about the sticky note itself getting in the way. We tried a few different ways of deciding which threshold to use. Our first attempt used 128, the midpoint of the greyscale pixel values. We had better success using k-means clustering on the pixel values to find groups of similar shades of grey e.g. text, sticky note and background, and using these to find a threshold between the text and the sticky note.
Even with these alterations, we were not very successful. This is likely because tesseract is optimised for reading printed documents and it has trouble recognising handwriting without retraining. Our sticky note reader had to recognise all handwriting, so even with retraining, we would not be able to get it to recognise the text we wanted.
Searching further we found a blog post [4] about training a handwriting detector, linked to a repo containing a pre-trained model. After cloning this and integrating it with our current pipeline we tested the model on our colour images and our pre-processing techniques but again had poor results.
Finally, we tested the OCR cognitive service offered by Microsoft Azure. This is a paid cloud service requiring calls to an azure server to carry out text detection. We tried the service by uploading a few images to their demo page and the accuracy on those images was much better than our previous attempts, achieving around 80%. It was fairly easy to set up a free trial and activate an endpoint we could use to detect text on sticky notes. Colour images gave us the best results, so we did not do any pre-processing or try to make the text clearer.
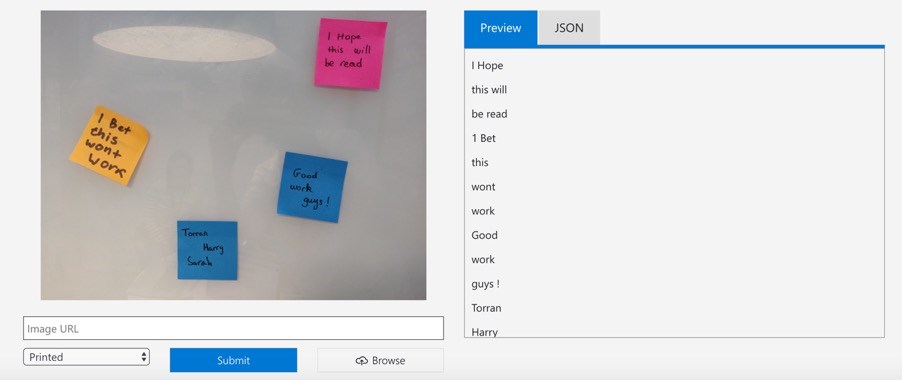
Trello integration
Trello board is an organisation tool using lists of ‘cards’, similar to sticky notes. As it has an extensive API, we could quickly create a new board from a user’s image with a card for each sticky note.
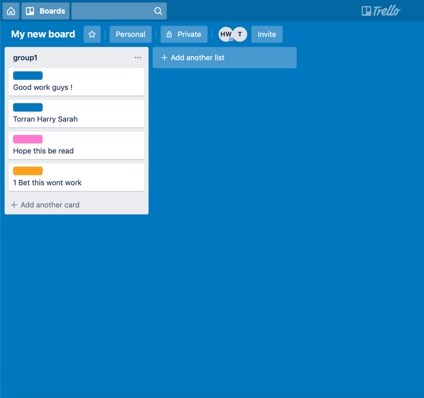
Trello also supports a limited set of coloured labels. Using the cropped image of each sticky note we calculated the average colour and compared it to the set of colours available in Trello, assigning this colour to it. This means that any colour coding originally used for the sticky notes is preserved in Trello! At this stage, each board is being created on one account and then shared with the user over email or using their existing Trello account. The Trello API supports user authentication, so a further development would be to incorporate this, removing the need for each Trello board to be initially produced on one main account.
Flask Web App
Now that we had the back-end working, we just needed a web app to allow a user to interact with it. We designed a simple website in HTML and used CSS to style it. Flask, a micro web framework for Python, was then used to create the web app, linking the website to the back-end software. We used Flask’s WTForm library to incorporate a form for the user to submit their photo and Trello account details into the website.
The web app included a button labelled ‘Trello’ which opened the form in a modal pop-up. Not the flashiest website in the world, but it does the job.
Results and Future
The web app meets all the requirements we set out for it initially. It can take a photo of a sticky note board and be given Trello account, and then extract each sticky note’s content, adding it to a new Trello board.
The text detection could be massively improved by using a handwriting recognition model rather than an OCR model, the latter being meant to detect printed text characters and not handwritten documents. The sticky note detector could be improved with a larger dataset, in addition, it could be trained over a greater number of steps using a cloud service. But for our purposes, the detector we trained on our local machine seems to achieve the desired result.
The web app could be developed further to have a more professional UI and incorporate additional features like a plain handwriting to text converter with no Trello output. Finally, as mentioned earlier, Trello’s user authentication features could be included to improve the confidentiality of the output.
All the code is available on github: https://github.com/valtech-uk/sticky-note-reader
References
[1] https://help.miro.com/hc/en-us/articles/360017572074-Sticky-Note-Recognition
[3] https://pythonprogramming.net/custom-objects-tracking-tensorflow-object-detection-api-tutorial/




